Abstract
With the rapid advancement of large language models (LLMs) and vision-language models (VLMs), significant progress has been made in developing open-vocabulary robotic manipulation systems. However, many existing approaches overlook the importance of object dynamics, limiting their applicability to more complex, dynamic tasks. In this work, we introduce KUDA, an open-vocabulary manipulation system that integrates dynamics learning and visual prompting through keypoints, leveraging both VLMs and learning-based neural dynamics models. Our key insight is that a keypoint-based target specification is simultaneously interpretable by VLMs and can be efficiently translated into cost functions for model-based planning. Given language instructions and visual observations, KUDA first assigns keypoints to the RGB image and queries the VLM to generate target specifications. These abstract keypoint-based representations are then converted into cost functions, which are optimized using a learned dynamics model to produce robotic trajectories. We evaluate KUDA on a range of manipulation tasks, including free-form language instructions across diverse object categories, multi-object interactions, and deformable or granular objects, demonstrating the effectiveness of our framework.
Overview
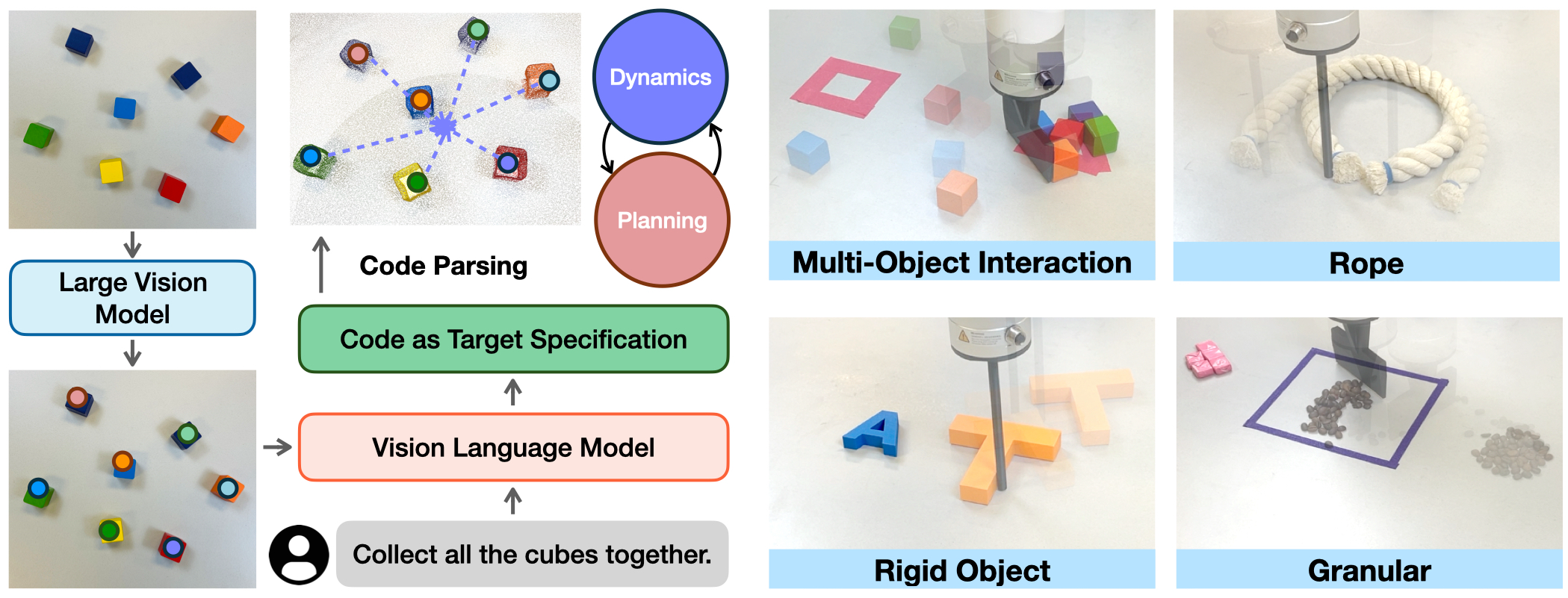
KUDA is an open-vocabulary manipulation system that unifies the visual prompting of vision language models (VLMs) and dynamics modeling with keypoints. Taking the RGBD observation and the language instruction as inputs, KUDA samples keypoints in the environment, then uses a VLM to generate code specifying keypoint-based target specification. These keypoints are translated into a cost function for model-based planning with learned dynamics models, enabling complex open-vocabulary manipulation across various object categories.
Method
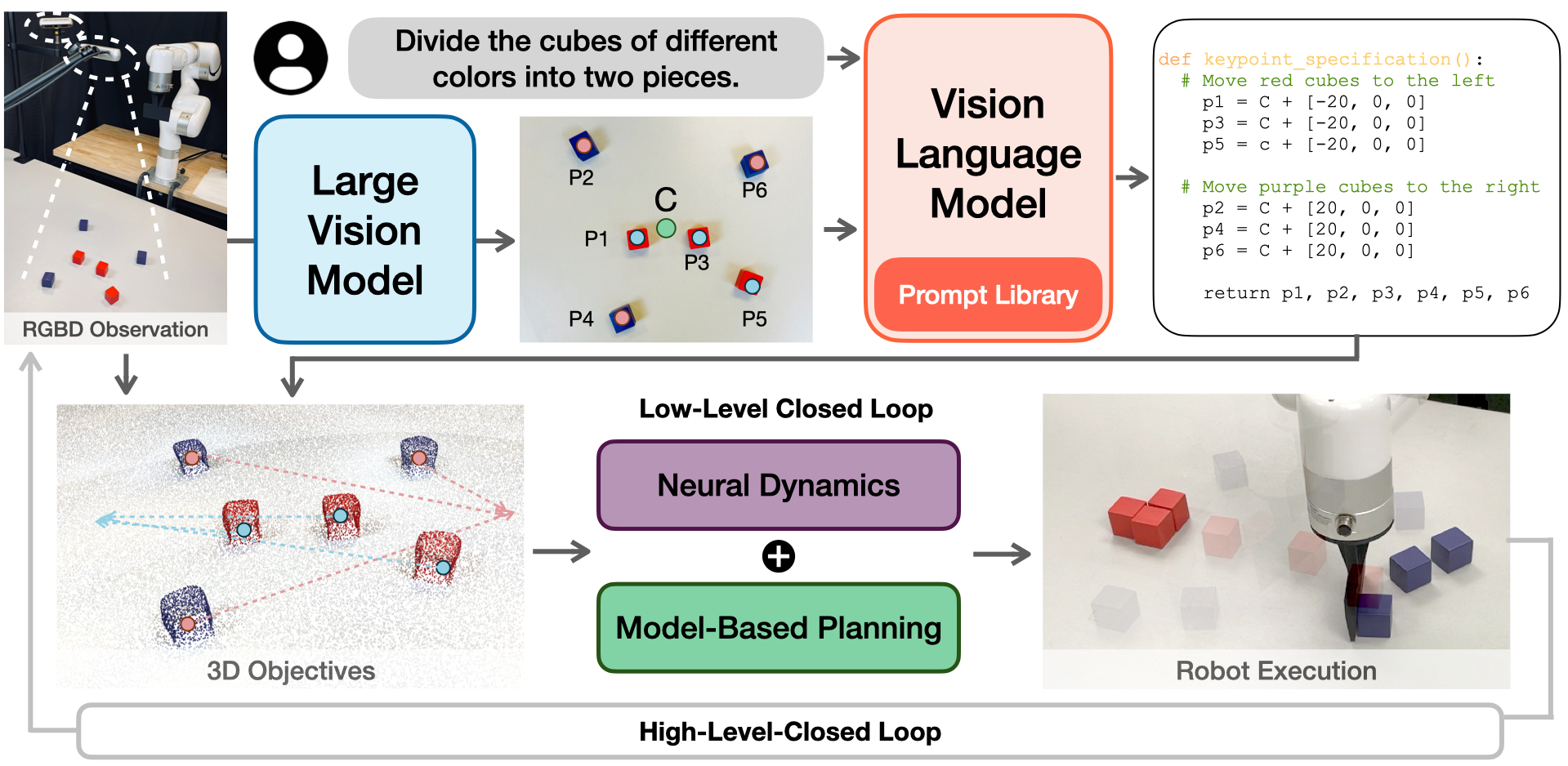
Taking the RGBD observations and a language instruction as inputs, we first utilize the large vision model to obtain the keypoints and label them on the RGB image to obtain the visual prompt (green dot C marks the center reference point). Next, the vision-language model generates code for target specifications, which are projected into 3D space to construct the 3D objectives. Last, we utilize the pre-trained dynamics model for model-based planning. After a certain number of actions have been performed, the VLM is re-queried using the current observation, enabling high-level closed-loop control to correct VLM errors.
Results
We show the target specification and robot executions of various tasks on different objects, highlight the effectiveness of our framework. We show the initial state and the target specification visualization of our system, along with the robot executions, to demonstrate the performance of our framework on various manipulation tasks. Note that we show the granular collection task to exhibit how our VLM-level closed-loop control works in our two VLM-level loops.
Real-World Results with Disturbances
Analysis: Error Breakdown of KUDA
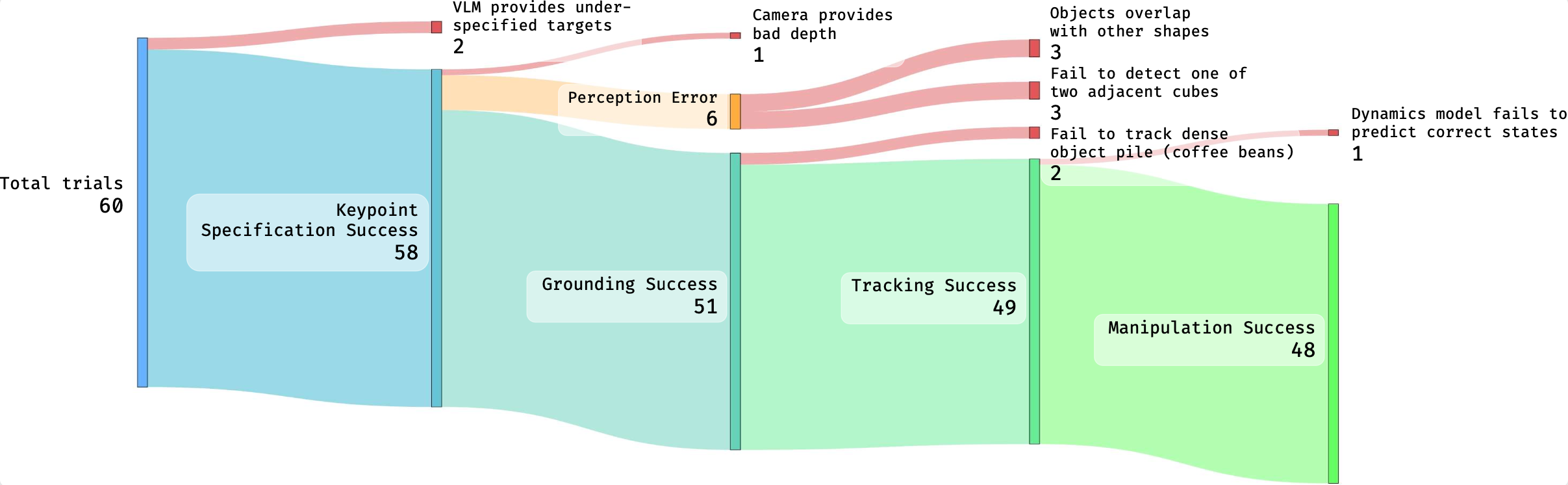
Success and failure cases during our evaluation, arranged by the process in a loop. We provide the detailed breakdown for each failure mode, marked with red. While we achieved a success rate of 80% on a total of 60 trials for various tasks, the leading causes of failure were perception errors, which accounted for 10% of the total trials and 50% of all the failure cases.
Bibtex
@misc{liu2025kudakeypointsunifydynamics,
title={KUDA: Keypoints to Unify Dynamics Learning and Visual Prompting for Open-Vocabulary Robotic Manipulation},
author={Zixian Liu and Mingtong Zhang and Yunzhu Li},
year={2025},
eprint={2503.10546},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2503.10546},
}